![[Mongo DB] Mongo DB시작하기](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FEe6y4%2FbtrZ9G1aJUd%2Fl99WBY8ry061rDyq1V7F61%2Fimg.png)

❓What Is Mongo DB
Mongo DB는 인기 있는 오픈 소스 NoSQL문서 지향형 데이터베이스 시스템입니다.
👉NoSQL란❓ "Not Only SQL"또는 "Non-Relational"의 준말로 기존의 관계형 데이터베이스가 아닌 다른 형태의 데이터 저장소를 의미합니다.
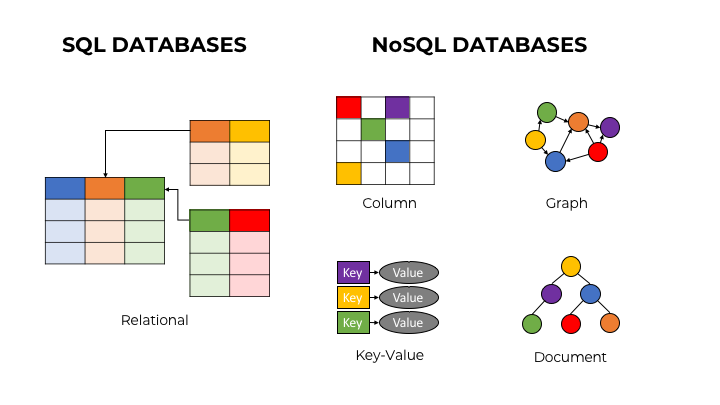
Mongo DB는 스키마(Schema)를 사전에 정의하지 않기 때문에 유연하고, 대량의 분산 데이터를 처리하는데 특화되어 있습니다.
👉스키마(Schema)❓ 기존의 데이터의 구조를 정의하는 데 사용하는 방법을 말합니다.(행, 열, json)

기존의 관계형 데이터베이스에서는 먼저 스키마를 정의하고 데이터를 삽입하는 방식으로 스키마를 변경하면 데이터를 다시 매핑해주어야 했지만
Mongo DB의 경우 스키마를 먼저 정의할 필요가 없기 때문에 json형태로 각 문서에 따라 다른 스키마를 가질 수 있어 데이터 삽입과 쿼리 작업이 굉장히 간단합니다.
🧮NoSQL 데이터 모델링
NoSQL 데이터 모델링은 관계형 데이터 모델링과는 다소 다른 방식으로 이루어집니다.
👉다음은 NoSQL 데이터 모델링을 수행하는 일반적인 절차입니다.
📌비즈니스 요구사항 분석
비즈니스의 요구사항을 분석해 필요한 데이터의 유형과 저장 방식등을 결정할 수 있습니다.
🔍대규모 데이터 저장
대규모 데이터 저장에는 분산 데이터베이스가 적합합니다.
👉여러 대의 서버에 데이터를 저장하고 처리하기 때문에 대용량 데이터를 처리할 수 있습니다.
📎대표적인 분산 데이터베이스로는 Apache Cassandra와 Apache HBase가 있습니다.

🔍실시간 데이터 처리
실시간 데이터 처리에는 In-memory데이터 베이스가 적합합니다.
👉위 방식은 데이터를 디스크 대신 메모리에 저장하므로 빠른 읽기 및 쓰기 성능을 제공합니다.
📎대표적으로는 Redis, Apache Ignite 및 Apache Geode와 같은 In-memory 데이터베이스가 있습니다.

🔍비정형 데이터 저장
비정형 데이터 저장에는 Document 데이터 베이스가 적합합니다.
👉위 방식은 JSON 또는 XML과 같은 문서 형식으로 데이터를 저장할 수 있습니다..
📎대표적으로는 MongoDB와 Couchbase는 Document 데이터베이스가 있습니다.

🔍그래프 데이터 저장
그래프 데이터 저장에는 Graph 데이터 베이스가 적합합니다.
👉위 방식은 노드와 에지로 구성된 복잡한 데이터를 처리하고 저장하는 데 적합합니다.
📎대표적으로는 Neo4 j, OrientDB 및 ArangoDB와 같은 그래프 데이터베이스가 있습니다.

🔍키 - 값 데이터 저장
키 - 값 데이터 저장에는 Key-value 데이터베이스가 적합합니다.
👉위 방식은 키와 해당 값으로 데이터를 저장합니다.
📎대표적으로는 Redis와 Riak과 같은 Key-value 데이터베이스가 있습니다.

🔍로그 데이터 처리
대량의 로그 데이터를 처리하려면 로그 데이터베이스가 적합합니다.
👉위 방식은 로그 데이터의 저장과 검색에 최적화되어 있습니다..
📎대표적으로는 Elasticsearch와 Splunk는 로그 데이터베이스가 있습니다.

🔍분산 캐싱
분산 캐시를 사용하여 데이터를 빠르게 가져오려면 Memcached와 같은 인메모리 캐시가 적합합니다.
👉위 방식은 데이터베이스는 캐시 데이터를 메모리에 저장하여 빠른 응답 시간을 제공합니다

📌데이터 모델링의 목적 결정
NoSQL의 경우 데이터 모델링의 목적이 기존의 관계형 데이터 베이스와는 다릅니다.
👉관계형 데이터베이스는 데이터를 정형화된 테이블로 구조화하여 저장하고 관리하는데 반해, NoSQL 데이터베이스는 비정형 데이터를 저장하고 관리하는 데 적합합니다.

🔍데이터의 유연성
NoSQL데이터 베이스는 스키마가 없거나 유연한 스키마를 사용하기 때문에 데이터의 변경과 추가가 용이합니다.
🔍수평적 확장성
NoSQL 데이터베이스는 수평적 확장이 가능합니다.
👉 데이터베이스 시스템이 확장될 때 샤딩 등의 기술을 사용하여 데이터를 분산 저장하므로, 더 많은 데이터를 저장하거나 더 많은 요청을 처리하기 위해 시스템을 확장할 수 있습니다.
🔍데이터를 복제 및 고가용성
NoSQL 데이터 모델링은 데이터의 복제와 고가용성에 중점을 둡니다.
👉데이터의 분산 및 복제를 허용하도록 설계되어 있어 이를 통한 시스템의 가용성과 데이터의 안정성을 보장할 수 있습니다.
🔍시스템 성능 향상
NoSQL 데이터베이스는 데이터의 접근 방식을 최적화할 수 있습니다.
👉쿼리를 효율적으로 처리하도록 데이터 구조와 인덱싱을 최적화해 시스템 성능을 향상할 수 있습니다.
📌데이터 구조 설계
NoSQL 데이터 모델링에서는 전통적인 관계형 데이터베이스의 ERD(Entity Relationship Diagram)와 같은 구조를 사용하지 않습니다.

덕분에 NoSQL 데이터베이스에서는 다양한 데이터 모델을 사용할 수 있습니다.
🔍Key-Value 데이터 모델
Key-Value 데이터 모델은 키와 값으로 이루어진 단순한 형태의 데이터 모델로, 키를 기준으로 데이터를 조회하고 저장합니다.
👉데이터의 빠른 읽기와 쓰기가 가능하며, 데이터베이스의 확장성도 용이합니다.

🔍Document 데이터 모델
Document 데이터 모델은 JSON 형태의 문서(document)로 데이터를 저장하는 형태입니다.
👉데이터 간의 관계를 구조적으로 표현하기 쉽고, 복잡한 데이터 구조를 다루기 쉽습니다.

🔍Columm-Family 데이터 모델
Column-Family 데이터 모델은 키-값 쌍으로 이루어진 로우(Row)를 하나의 패밀리(Column-Family)로 묶어 저장하는 모델입니다.
👉각 패밀리는 여러 개의 칼럼(Column)으로 이루어져 있으며, 각 칼럼은 이름, 값, 타임스탬프 등의 정보를 가지고 있습니다.

🔍Graph 데이터 모델
Graph 데이터 모델은 노드와 에지로 이루어진 그래프(graph) 형태의 데이터 모델입니다.
👉노드는 객체(object)를 나타내며, 에지는 객체 간의 관계를 나타냅니다.

📌인덱스 설계
NoSQL 데이터베이스에서는 데이터 검색 속도를 향상하기 위해 인덱스를 사용합니다.
👉인덱스를 설계하는 법은 다음과 같습니다.
1. 쿼리 분석
어떤 쿼리가 수행되는지, 쿼리에 어떤 필드가 사용되는지 분석해야 합니다.
2. 필드 선택
분석한 쿼리에서 자주 사용되는 필드를 선택해야 합니다.
👉불필요한 필드를 인덱싱 하면 인덱스를 생성하는데 오랜 시간이 걸리고, 인덱스 용량이 커져 성능 저하가 일어날 수 있습니다.
3. 인덱스 유형 선택
NoSQL 데이터베이스는 다양한 인덱스 유형을 제공합니다.
Key-Value Store: 해시 인덱스
Document Store: B-Tree 인덱스, Geospatial 인덱스, Full-text 검색 인덱스, Bitmap 인덱스, Multi-key 인덱스 등
Column-Family Store: SSTable과 LSM-Tree를 기반으로 한 인덱스, 슈퍼칼럼 인덱스 등
Graph Database: 노드, 에지, 속성 등을 인덱싱할 수 있는 고유의 인덱스 유형이 존재합니다.
각 데이터베이스마다 어떤 유형의 인덱스가 있는지, 각각의 장단점은 무엇인지 파악하고 적합한 유형을 선택해야 합니다.
4. 인덱스 구성
인덱스를 구성할 때는 필드의 크기, 유형 등을 고려해야 합니다.
👉문자열 길이 최소화, 대소문자 구분등에 대한 처리방식
5. 인덱스 유지 보수
인덱스는 데이터의 추가, 수정, 삭제 작업에 따라 유지 보수가 필요합니다.
👉따라서 유지보수에 필요한 자원과 성능에 대한 고려가 필요합니다.
6. 인덱스 성능 모니터링
인덱스의 성능을 모니터링하고, 필요에 따라 인덱스를 재구성하거나 삭제하는 작업이 필요합니다.
📌클러스터링 및 파티셔닝 설계
NoSQL 데이터베이스는 데이터를 분산하여 저장하므로, 클러스터링 및 파티셔닝 설계가 중요합니다.
🔦클러스터링(Clustering)
클러스터링은 데이터를 저장할 때 특정한 방법으로 데이터를 그룹화하는 것입니다.
이를 통해 데이터를 특정 기준에 따라 분류할 수 있고, 검색 시 해당 그룹에서 검색을 수행함으로써 성능을 향상할 수 있습니다.
💡파티셔닝(Partitioning)
파티셔닝은 데이터를 여러 파티션으로 나누어 저장하는 것을 의미합니다.
이를 통해 데이터를 분산하여 저장하고, 시스템의 확장성을 높일 수 있습니다.
예))사용자의 로그 데이터를 저장하는 경우, 데이터의 양이 많아지는 경우 데이터를 시간별로 파티셔닝 하여 적절한 서버에 저장합으로써 성능을 향상할 수 있습니다.
💻몽고 DB의 기본 개념
대표적인 몽고 DB의 용어와 개념은 다음과 같습니다.
📌Document
몽고 DB에서 데이터는 Document 단위로 저장됩니다.
Document는 JSON 형식으로 저장되며, 필드-값 쌍(key-value pair)의 집합으로 구성됩니다.
📌Collection
Document 들의 집합으로, 관련된 Document 들을 그룹화하여 저장합니다.
RDBMS에서의 테이블과 유사한 개념이며, Document 들은 컬렉션 내에 저장됩니다.
👉RDBMS란❓ Relational Database Management System의 약자로, 관계형 데이터베이스 관리 시스템을 의미합니다.
📌Database
몽고 DB에서 컬렉션의 집합을 데이터베이스(Database)라고 합니다.
각 데이터베이스는 컬렉션을 관리하며, 컬렉션은 하나의 데이터베이스에 속합니다.
📌Index
데이터베이스 내에서 검색 경로를 만들어 주는 데이터 구조를 의미합니다.
일반적으로 B-tree 인덱스를 사용하지만, 텍스트 검색용 인덱스나 지리적(Geospatial) 인덱스 등도 지원합니다.
📌Shard
몽고DB에서 데이터베이스를 여러 서버에 분산하여 저장하는 방식을 샤딩(Sharding)이라고 합니다.
👉데이터를 파티션으로 분할하고, 파티션을 각 서버에 배치합니다.
📌Replica set
여러 대의 서버에 동일한 데이터를 복제하여, 하나의 서버에 문제가 생겨도 다른 서버에서 서비스를 제공할 수 있도록 합니다.
📌Aggregation
몽고DB에서 데이터를 집계하거나, 여러 컬렉션의 데이터를 조합하여 결과를 반환하는 기능을 제공합니다.
👉SQL의 GROUP BY와 비슷한 개념으로, 파이프라인(pipeline)을 이용하여 데이터를 처리합니다.
❓ SQL에서 GROUP BY는 특정 열(column)을 기준으로 데이터를 그룹화하는 명령어입니다.
🔠몽고 DB의 쿼리 언어
몽고DB의 쿼리 언어인 MongoDB Query Language (MQL)은 SQL과 유사한 구문을 가지고 있으며, NoSQL 데이터베이스에 맞게 일부 기능이 추가된 형태의 언어입니다.
📁자주 사용되는 연산자
MQL의 검색과 조작 작업은 간단한 문법으로 많은 작업을 수행할 수 있습니다.
1. $eq, $ne, $gt, $gte, $lt, $lte
다음은 비교 연산자입니다. 각각 equal to, not equal to, greater than, greater than or equal to, less than, less than or equal to에 해당합니다.
db.users.find({ age: { $gt: 30 } })
//'user' Collection에서 'age'필드가 30보다 큰 Documnet를 검색합니다.2. $in, $nin
$in 연산자는 특정 값을 가지는 Document를 검색할 때 사용됩니다. 반대로 $nin 연산자는 특정 값을 가지지 않는 Document를 검색합니다.
db.users.find({ age: { $in: [25, 30, 35] } })
//'users' Collection에서 'age' 필드가 25, 30, 35 중 하나인 Document를 검색합니다.3. $and, $or, $not
다음은 논리 연산자로
$and : 연산자는 두 가지 이상의 조건을 모두 만족하는 Document를 검색합니다.
$or : 연산자는 두 가지 이상의 조건 중 하나 이상을 만족하는 Document를 검색합니다.
$not : 연산자는 주어진 조건을 만족하지 않는 Document를 검색합니다.
db.users.find({ $and: [{ age: { $gt: 30 } }, { gender: "male" }] })
//"users" Collection에서 "age" 필드가 30보다 크고 "gender" 필드가 "male"인 Document를 검색합니다.4. $exists
$exists 연산자는 특정 필드가 존재하는 Document를 검색합니다. $exists 연산자는 true 또는 false 값을 가질 수 있습니다.
db.users.find({ address: { $exists: true } })
//"users" Collection에서 "address" 필드가 존재하는 Document를 검색합니다.5. $regex
$regex 연산자는 정규 표현식을 이용하여 특정 패턴을 가지는 Document를 검색합니다.
db.users.find({ name: { $regex: /^a/i } })
//"users" Collection에서 "name" 필드가 a로 시작하는 Document를 검색합니다. i 플래그는 대소문자를 구분하지 않도록 설정합니다.6. $set, $unset, $inc
다음은 Document를 조작하는 연산자입니다.
$set : 연산자는 특정 필드의 값을 변경하거나 추가합니다.
$unset : 연산자는 특정 필드를 제거합니다.
$inc : 연산자는 특정 필드의 값을 증가시킵니다.
db.users.update({ name: "Alice" }, { $inc: { age: 1 } })
//"users" Collection에서 "name" 필드가 "Alice"인 Document를 찾아서 age 필드의 값을 1 증가시킵니다.7. $push, $pull
다음은 배열을 조작하는 연산자입니다.
$push : 연산자는 배열의 끝에 새로운 값을 추가합니다.
$pull : 연산자는 배열에서 특정 값을 제거합니다.
db.users.update({ name: "Alice" }, { $push: { hobbies: "swimming" } })
//"users" Collection에서 "name" 필드가 "Alice"인 Document를 찾아서 hobbies 배열의 끝에 "swimming" 값을 추가합니다.
📝몽고DB의 인덱스
인덱스(Index)는 Collection의 검색 속도를 높이기 위한 방법입니다.
👉인덱스를 사용하면 Collection을 검색할 때 전체 Document를 대상으로 하지 않고, 인덱스가 지정된 필드를 기준으로 검색을 수행합니다.
📌단일 필드 인덱스(Single-field index)
단일 필드 인덱스는 하나의 필드를 기준으로 검색할 때 매우 효과적인 검색을 수행할 수 있습니다.
db.users.createIndex({ name: 1 })📌복합 인덱스(Compound index)
복합 인덱스 2개 이상의 필드를 기준으로 검색할 때 효과적인 검색을 수행할 수 있습니다.
db.users.createIndex({ name: 1, age: -1 })📌텍스트 인덱스(Text index)
텍스트 인덱스 특정 텍스트를 포함한 Document를 검색할 때 효과적인 검색을 수행할 수 있습니다.
db.articles.createIndex({ content: "text" })
🔧몽고DB의 드라이버
📌MongoDB Java Driver
Java에서 몽고 DB를 다루기 위한 드라이버입니다.
👉MongoClient 클래스를 통해 몽고 DB와의 연결을 제공하고, DBCollection 클래스를 통해 데이터베이스 컬렉션을 다룹니다.
/*설치 방법*/
https://mongodb.github.io/mongo-java-driver/ 에서 다운로드📌PyMongo
Python에서 몽고 DB를 다루기 위한 드라이버입니다.
👉MongoClient 클래스를 통해 몽고 DB와의 연결을 제공하고, Collection 클래스를 통해 데이터베이스 컬렉션을 다룹니다.
/*설치 방법*/
pip install pymongo📌MongoDB Node.js Driver
Node.js에서 몽고 DB를 다루기 위한 드라이버입니다.
👉MongoClient 클래스를 통해 몽고 DB와의 연결을 제공하고, Collection 클래스를 통해 데이터베이스 컬렉션을 다룹니다.
/*설치 방법*/
npm install mongodb📌Ruby Driver for MongoDB
Ruby에서 몽고 DB를 다루기 위한 드라이버입니다.
👉MongoClient 클래스를 통해 몽고 DB와의 연결을 제공하고, Collection 클래스를 통해 데이터베이스 컬렉션을 다룹니다.
/*설치 방법*/
gem install mongo📌MongoDB C# Driver
C#에서 몽고 DB를 다루기 위한 드라이버입니다.
👉MongoClient 클래스를 통해 몽고 DB와의 연결을 제공하고, IMongoCollection 인터페이스를 통해 데이터베이스 컬렉션을 다룹니다.
/*설치 방법*/
1. Visual Studio를 엽니다.
2. 새로운 프로젝트를 만들고, Solution Explorer에서 프로젝트 이름을 마우스 오른쪽 버튼으로 클릭합니다.
3. 나타나는 메뉴에서 "Manage NuGet Packages"를 선택합니다.
4. NuGet 패키지 매니저가 열리면, 검색 창에 "MongoDB.Driver"를 입력합니다.
5. 검색 결과로 나타나는 MongoDB.Driver 패키지를 선택하고, "Install" 버튼을 클릭합니다.
6. 패키지 매니저에서 MongoDB.Driver를 설치하는 동안 필요한 패키지들도 함께 설치됩니다.
7. 설치가 완료되면, MongoDB.Driver 네임스페이스를 사용하여 MongoDB와 연결하고 쿼리를 실행할 수 있습니다
🔥몽고DB 시작하기
💻몽고 DB설치하기
다음 사이트를 참고해서 몽고 DB를 설치해 주세요
👉맥 OS의 겨우 몽고 DB를 홈브루를 이용해 설치할 수 있습니다.
https://khj93.tistory.com/entry/MongoDB-Window%EC%97%90-MongoDB-%EC%84%A4%EC%B9%98%ED%95%98%EA%B8%B0
[MongoDB] Windows에 MongoDB 설치하기
MongoDB 몽고 DB는 Document 지향 데이터베이스 시스템으로 대표적인 NoSQL DB입니다. 오늘은 그러한 MongoDB를 Winodws에 설치 방법에 대해 포스팅을 해보려고 합니다 1. 설치 하기 설치 링크 : www.mongodb.com/t
khj93.tistory.com
MongoDB를 설치하고 MongoDB Compass를 실행해 주세요

MongoDB Compass는 MongoDB 데이터베이스의 시각화 및 관리 도구입니다.
👉MongoDB Compass는 직관적인 사용자 인터페이스와 다양한 기능을 제공하므로, MongoDB 데이터베이스를 관리하는 데 매우 유용합니다.
🔌서버와 연결하기
MongoDB Compass에서 "Connection"은 MongoDB 데이터베이스 서버와의 연결 작업이 필요합니다.

MongoDB는 NoSQL 데이터베이스이며, 여러 대의 서버에 데이터를 분산시키는 클러스터링을 지원하기 때문에, MongoDB Compass에서 Connection 작업은 데이터베이스 서버와 연결하는 작업을 말합니다.
🔍Advanced Connection Options
Advanced Connection Options을 통해 host, Authentication 등을 설정할 수 있습니다.

기본값은 다음과 같이 mongodb://localhost:27017로 설정되어 있으며 변경 가능합니다.
👉데이터의 인증값을 설정하거나 proxy, ssh설정등을 마친 후 Connect를 누르게 되면 해당 local서버와 연결되게 됩니다.
📝Document CRUD
MongoDB Compass에서 처음 시작하면, 데이터베이스 목록에서 기본적으로 세 가지 데이터베이스가 표시됩니다.

admin : 이 데이터베이스는 시스템의 관리를 위한 데이터베이스입니다. 이 데이터베이스에는 사용자 인증 및 권한 설정과 같은 시스템 관리 작업을 위한 컬렉션이 포함되어 있습니다.
config : 이 데이터베이스는 MongoDB 샤딩을 위한 데이터베이스입니다. 이 데이터베이스는 샤드 클러스터의 구성 및 관리 작업에 사용됩니다.
local : 이 데이터베이스는 MongoDB에서 로컬 스토리지 엔진과 관련된 데이터를 저장하기 위한 데이터베이스입니다. 이 데이터베이스에는 섀딩 된 클러스터에서 사용되는 라우팅 정보, 캐시 및 로컬 데이터 저장소가 포함됩니다.
👉위와 같이 몽고 DB는 컬렉션이라는 개념을 제공하여 비슷한 document끼리 그룹화 할 수 있습니다.
1. Creat
데이터베이스를 작성하기 위해서는 먼저 우측상단에 "Create Database"클릭해 Collection이름과 데이터 베이스 이름을 만들어 주세요

Create Database를 클릭하게 되면 db.Pizza라는 데이터 베이스가 생기게 됩니다
👉다음으로 Pizza라는 이름의 컬렉션으로 들어가 "ADD DATA"에 "Insert document"를 클릭하여 데이터를 추가해 주세요

2. Read
Fitter기능을 사용하면 쉽게 데이터를 조회할 수 있습니다.
{filed : filed의 값}을 입력한 다음 "find"를 누르게 되면 해당 데이터가 조회됩니다.

3 Update
데이터를 수정할 때에는 해당 데이터의 filed값을 클릭한 다음 수정한 다음 아래 생기는 "UPDATE"버튼을 누르면 됩니다.

4. Delete
삭제 시에도 위에 상단에 쓰레기통 모양 아이콘을 클릭하게 되면 데이터가 삭제 되게 됩니다.

728x90
반응형
'백엔드' 카테고리의 다른 글
| [Java] Java 시작하기 (1) | 2023.05.07 |
|---|---|
| [Go]Go lang 사용해 보기 (0) | 2023.03.21 |